Spark 구성
Spark는 Drvier 프로세스 1개와 다수의 Executor, 그리고 1개의 Cluster Manager로 구성된다.
Spark 구성 별 역할
SparkDriver
- 유저의 진입점이다. SparkSession or SparkContext를 초기화하고, 각 작업을 Executor에게 분배한다.
- 사용자의 실행 코드를 실행 계획(DAG) 로 변환한다.
- Cluster Manger 와 통신하여 Executor를 할당받는다.
- Driver가 Cluster에서 실행되면 Cluster 모드, 외부에서 실행하면 Client 모드라고 한다.
Cluster Manager
- 리소스 매니저, SparkDriver에게 리소스를 요청받으면 가용 Executor를 할당해 준다.
- Yarn, mesos, kubernetes 등이 주로 사용되며, Databricks, Glue 등은 자체 Cluster Manager를 사용한다.
- Cluser Manager를 다른 서비스를 사용하지 않고 스파크 자체에서 처리하면 StandardAlone 모드라 한다.

Executor
- Driver 가 나눠준 Task를 수행하고 결과를 반환한다.
- 각 Executor는 독립된 JVM 프로세스로 실행된다.
그렇다면 Worker Node, Master Node는?
Spark 구성을 보다 보면 저런 Node에 관한 설명도 보이는데 Node는 물리적 단위이다.
예를 들어 Executor는 Worker Node에서 실행되는 프로세스이고,
Master Node는 Cluster Manager를 실행하는 역할이다.(StandardAlone 모드)
외부 Cluster Manager 를 사용할 경우 해당 시스템의 리소스로 대체 가능하다.

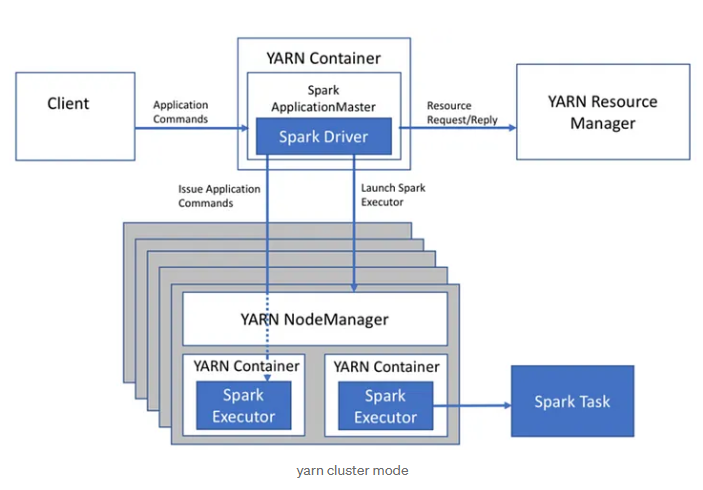
Spark 실행흐름
아래 그림을 참조하며 플로우를 그려보면 이해가 쉽다.

1. 작업 요청
- 사용자가 SparkDriver를 통해 작업 실행을 요청하면, SparkSession 또는 SparkContext 가 초기화 된다.
2. SparkSession과 Cluster Manager 연결
- SparkSession 은 SparkContext를 생성하고 이를 Cluster Manager와 연결한다.
3. Driver 가 작업을 실행 계획으로 변환 (DAG 생성)
- 사용자가 작성한 코드를 RDD나 Dataframe 연산으로 변환한다.
- 변환된 연산을 기반으로 실행 계획을 생성한다.
- 실행 계획을 Catalyst Optimizer를 이용해 최적화한다.
4. job 및 Task 분할
- Driver는 실행계획을 기반으로 작업을 구성한다. 각 작업은 Stage로 나뉜다.
5. Executor를 배치
- Cluster manager는 Executor를 WorkerNode에 배치한다.
6. Executor에게 Task 분배
- Driver는 Executor에게 Task를 직접 분배한다.
7. 결과 반환
- Executor 가 실행 결과를 Driver로 반환하거나 저장한다.
마무리
Glue, EMR, Databricks와 같은 서비스는 이런 상세 구조를 알지 못해도 쉽게 실행할 수 있도록 되어있다.
다만 많은 데이터를 다루고 각각의 분석 요건에 따라 구성하려면 상세한 구조를 파악해야 적재적소에 배치해 사용할 수 있다고 생각한다.
참고
https://www.databricks.com/kr/glossary/what-are-spark-applications
Spark 애플리케이션
Spark 애플리케이션은 driver 프로세스 하나와 일련의 executor 프로세스로 구성됩니다. driver 프로세스는 main() 함수를 실행하고 클러스터 내 노드에 위치하며 세 가지 작업을 담당합니다. 하나는 S
www.databricks.com
https://medium.com/@goyalsaurabh66/running-spark-jobs-on-yarn-809163fc57e2
Running Spark Jobs on YARN
When running Spark on YARN, each Spark executor runs as a YARN container. Where MapReduce schedules a container and fires up a JVM for…
medium.com
https://spark.apache.org/docs/3.5.3/running-on-kubernetes.html
Running Spark on Kubernetes - Spark 3.5.3 Documentation
Running Spark on Kubernetes Spark can run on clusters managed by Kubernetes. This feature makes use of native Kubernetes scheduler that has been added to Spark. Security Security features like authentication are not enabled by default. When deploying a clu
spark.apache.org
'IT 기술 > 데이터엔지니어링' 카테고리의 다른 글
| k8s에 Airflow helm 으로 배포하기 - dags,logs 폴더 마운트 (0) | 2025.02.26 |
|---|---|
| [Spark] Structured Streaming으로 실시간 데이터 처리하기 - Databricks 활용 (0) | 2024.12.16 |
| [Spark] Shuffle 이란? - Wide Transformation, Narrow Transformation (0) | 2024.11.28 |
| [Spark]UDF 의 정의 및 사용 방법 + UDF 별 수행 속도차이(PySpark)- 24.11 (1) | 2024.11.27 |
| [Spark] Databricks Community Edition 무료로 사용하기 -2024.11 (1) | 2024.11.20 |